Day 1
Coding
- Start with Grind 75 Leetcode list
- Post Order Travelsal:
- Calculate something at each node using value’s from node’s left and right subtree
System Design
- General Approach (for business problems):
- Requirements: Functional & Non-Functional
- Core Entities
- API or Interface
- High Level Design
- Deep Dives
PS: Only do calculation when it impacts the design
- CAP Theorem
- Partitaion failure tolerance usually is a must have. Make trade off between consistency and availability.
- Availability: multi replicas, CDC + Eventual Consistency
- (Strong) Consistency: distributed transactions, single active node
- Different consistency types: Strong, Causal, Read-after-writes, Eventual
- Design Youtube Top K Videos
- Core entities: Video, View, Time Window
- Video view event stream
- Using counter to tack
<video_id, view_count>and maintian a top-K heap - Using checkpoint to recover host
- Handling Time window:
- Hour Counter, Day Counter, Minute Counter
- Two pointer approach: 1 “rising edge” add count, 3 “failiing edges” decrement the count. Kafka offsetsForTimes)

- Design Ticket Master
- Core entities: Event, Venue, Performer, Ticket, User, Booking
- Ticket Reserving: using Redis as a distributed lock, Ticket table only needs two state: available and booked
- High-demand Event: vitual waiting queue, estibilished a websocket connection
- Improve Search: primary database to ElasticSearch

Day 2
Coding
- Container with most water : two pointers, left and right, move the smaller one in each step
- 3Sum: sort array first, fix one number and use two pointers to find another two.
System Design
- Design Uber
- Core entities: Rider, Driver, Fare, Ride, Location
- Frequent driver location updates & efficient searches on location data:
- real time in-memory Geo Hash based storeage. e.g. Redis, Valkey
- batch insert into geospatial databases, e.g. PostGIS, which is based on quad-trees
- Avoid system overload from frequent driver location updates: adaptive location update intervals on client side
- Consistent match: sending request to one driver each time, wait 10s for the next driver
- Prevent multi ride requests sent to the same driver: using Redis as a distributed lock with TTL

- Design Drop Box
- Core entities: File, File Metadata, User
- Upload file directly to S3: using S3 pre-signed URL, Download file from CDN
- Upload large file (50 GB):
- chunk files on client to 5mb chunk
- add a
chunksfield in fileMetadata table. update it from S3 notification - identify which chunk has been uploaded: fingerprint
- Fast uploads, downloads and syncing: compression, sending multiple chunks in parallel, adaptive chunk sizes, identify which chunks have changed
- Security: encryption in transit (HTTPs), encryption on storage, access control (signed URL with TTL)

- Dive Deep - Kafka
- Terminolog and Architecture:
- Broker: the server which hold queues.
- Partition: the “queue”. immutable, ordered. A broker can hold multiple partitions
- Topic: a logic group of partitions
- Producer: write data to topics
- Consumer: read data from topics.
- Consumer Group: each event only processed by one consumer in the group.
- Availability & Duriability: each partition has a leader replica (for both write and read) and follower replica(s).
- Scalability: horizontal scaling with more brokers, partitioning strategy: choose a good partition key
- Handling Retries and Errors: retry queue, DLQ
- Why so fast: 1. sequential disk writes 2. zero-copy IO 3. parallel processing - partitioning 4. batching and comperssion 5. memory-mapped files
- Terminolog and Architecture:

Day 3
Coding
- LRU Cache: double linked list + hash map
- Word Break: DP with two pointers:
dp[i]means sub string ends at index i can break.dp[i] = for j in 0->i: dp[j] && wordDict.contains(s.subString(j, i).
System Design
- Dive Deep - Dynamo DB
- Predictable, Low Latency, At Any Scale
- Core Concepts:
- Partition Key: determine the physical location of the item within the database - Consistent Hashing
- Sort Key: used to order items with the same partition key value - B-tree
- Global Secondary Index (GSI): an index with a partition key and optional sort key that differs from the table’s partition key. (up to 20 GSIs per table)
- Local Secondary Index (LSI): an index with the same partition key as the table’s primary key but a different sort key. (up to 5 LSIs per table)
- Consistency Types:
- Eventual Consistency: writes to a primary replica, replicated to seondary ones async; reads are served by any replica.
- Strong Consistency: use Multi-Paxos for writes; reads reflect the most recent write, are routed to leader replica.
- Conflict resolution: last writer wins
- Transaction Support: two-phase commit protocol across muliple partitions.
- AWS re:Invent 2024 - Dive deep into Amazon DynamoDB (DAT406)
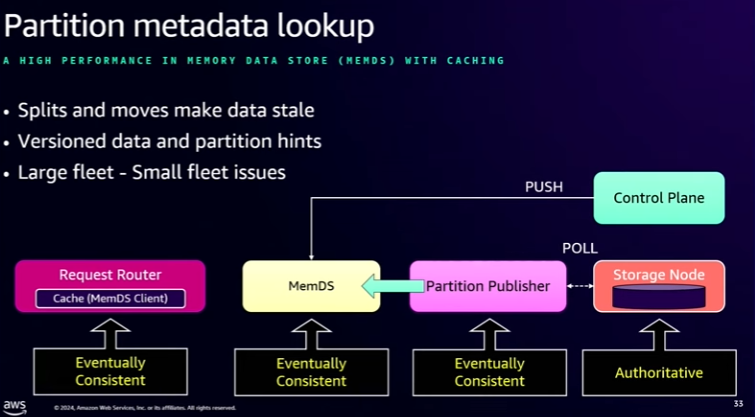
- Partition Metadata Lookup: Request Route (local cache) -> MemDS <- Partition Publisher –poll– Storage Node.
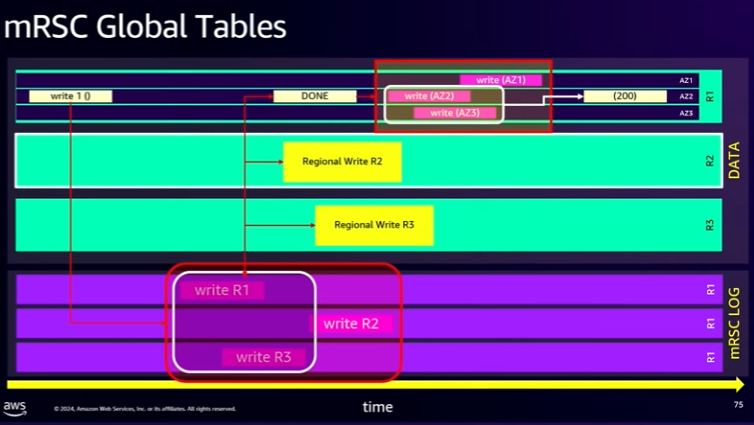
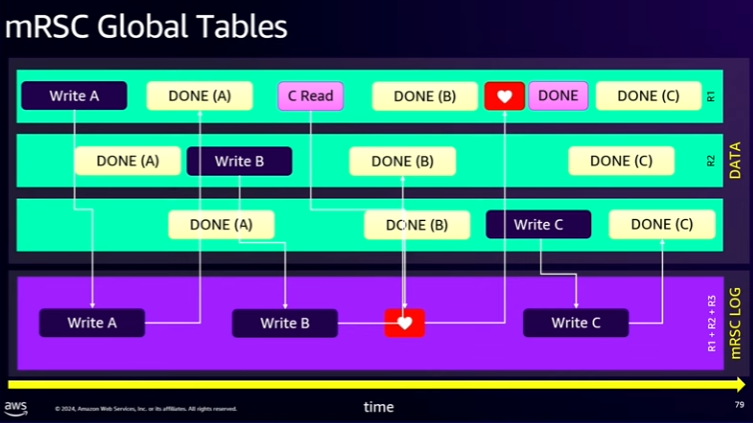
- mRSC Global Tables: global read-after-write consistency.
Day 4
Coding
- Heap: complete binary tree.
PriorityQueuein Java.- Binary heap: tree root at index 0, for node at index i: children at 2i+1 and 2i+2, parent at floor((i-1)/2)
- Time complexity: find-min: O(1), delete-min: O(log n), decrease-key: O(log n), insert: O(log n), build-heap: O(n)
System Design
- General Approach (for infrastructure problems):
- Requirements: Functional & Non-Functional
- System Interface & Data Flow
- High Level Design
- Deep Dives
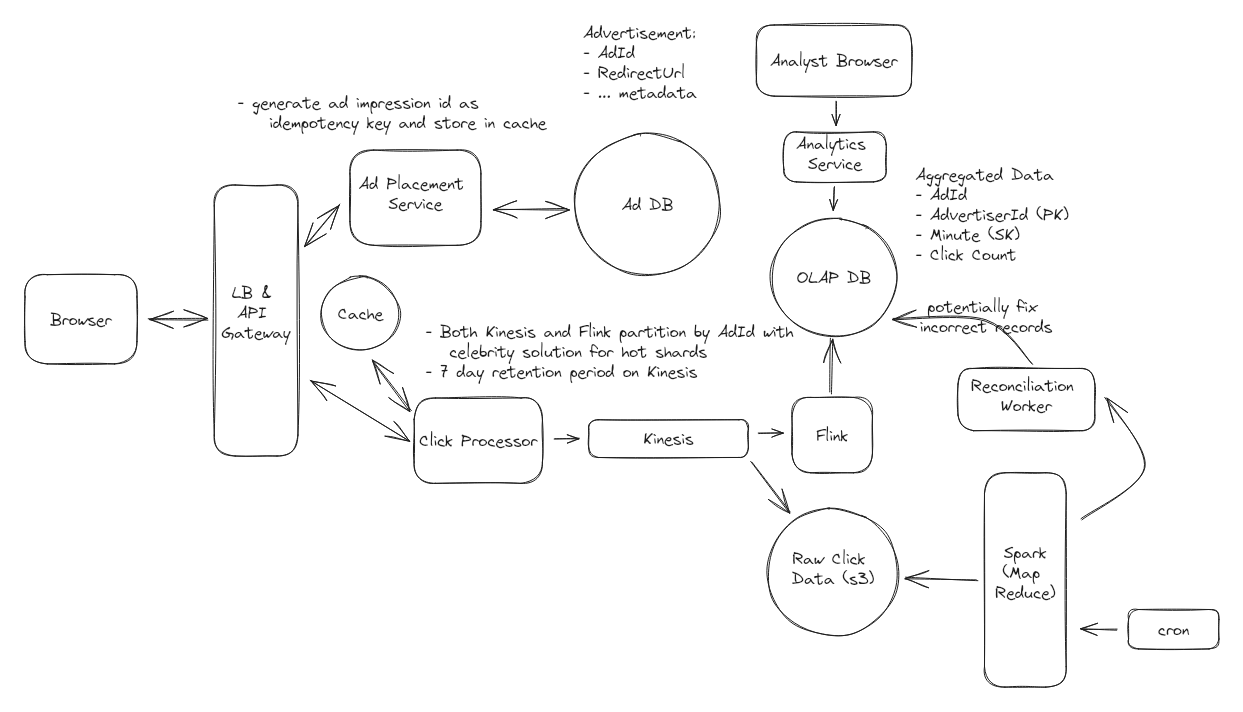
- Ad Click Aggregator
- Ad click redirect: server side redirect
- Do not lose any click data:
- retention period on stream
- reconciliation: store raw data and use an offline job to recalculate metrics
- Prevent abuse from users clicking: generate unique impressions id on server side, signed impression id with a secret key, use a distributed cache to verify whether it exists
- Facebook News Feed/Twitter
- Core entities: User, Follow, Post
- Handle users who following a large number of users: maintian a precomputed
Feedtable. - Handle users with a large number of followers: use an aync feed worker, ignore users with large followers, hybrid approach when read
- Uneven reads of Posts table: redundant post cacche

Day 5
Coding
- Binary Search: find the target value from a sorted array. O(log n)
- Time Based Key-Value Store: HashMap + (sorted) List, using binary search to find the floor timestamp for
get. - Min Stack: two stacks: one regular stack for tracking oder, one monotonic stack for
popfunction incase min value change. - Find median from Data Stream: two heaps: one max heap for numbers on the left side, one min heap for numbers on the right side.
System Design
- Dive Deep - Log-Structured Merge Tree in Database
- writes in a fast in-memory data structure (e.g. red-black tree, AVL tree)
- flush to disk as an immutable table (SSTable)
- periodically, small on-disk files are mreged into large sorted files
- reads are sreved by first checking the in-memory structure, followed by searching disk-based sorted files.
- bloom filter/sparse index are used for quickly determine if a key exists in a specific file.
- B-Tree vs Log-Structured Merge Tree
Day 6
Coding
- 01 Matrix: BFS, start with 0, ininiate non-0 point with -1, use
result[new_i][new_j] >=0to verify a point has been visited. - Merge k Sorted List: use recurision to convert the problem to MerageTwoSortedLists.
- Diameter of Binary Tree: Post order traversal
System Design
- [Dive Deep - AWS Lambda]
Day 7
Coding
- Combination Sum: backtracking
- Majority Element: moore voting algorithm
- Serialize and Deserialize Binary Tree: preorder travelsal (DFS): deserialize using a queue with all nodes, recursively; in-level travelsal (BFS): deserilize using a queue with the first node and a counter.
System Design
- Url Shorter
- Core entiteis: Original URL, Shor URL, User
- Ensure short urls are unique: Unique Counter with Base62 Encoding
- Ensure redirects are fast: in-memory cache / CDN
- Support 1B shortened urls aand 100M DAU: database replication & backup, Redis as a distributed counter

- Web Crawler
- System Interface: Input: Seed URLs to satrt crawling from; Output: Text data extracted from web pages.
- Ensure fault tolerant:
- break Crawler into two stages: URL Fetcher, Text & URL Extractoin.
- Handle failure of fetch a URL: SQS with exponential backoff.
- Politeness
- add last time we crawled each domain into meta data table
- rate limit 1 second: sliding window algorithm, jitter: a random delay
- Scale to 10B pages and efficiently crawl < 5 days:
- avoid duplicate: hash and store in metadata DB w/ Index or Bloom Filter?
